Project Dolly Shield Final: Integrating Large Language Models into Enterprise System Architectures

Summary and Learnings from Results
The results below show that caution is the best approach when implementing large language models in enterprise settings. There’s an incredible amount of nuance involved and product requirements need to be flexible and highly iterative, with strong preference given to rapid prototyping in sandboxed environments . I certainly did hundreds of rapid fire prompt iterations before settling on comparing two throughout the research.
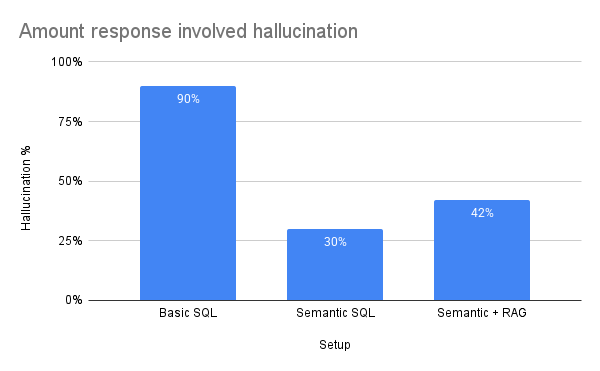
Semantic SQL alone being the overall preferred result is a function of the relationship between the data in the SQL database and the documents in the document store. I scraped topically relevant stories from DJ Mag but there wasn’t an inherent link between these stories and the data in the SQL database. As a result, I struggled with getting a semantic + RAG answer that felt related. To state the obvious, there needs to be a strong semantic relationship between the SQL database data and the document store data, otherwise the model will struggle to find relevant chunks for retrieval.
Hallucinations are a serious issue, but they are also highly nuanced. Much depends on the technical details of how the LLM interacts with the SQL database and how the database executes queries. Opting for an out of the box solution from providers like Snowflake or Databricks means sacrificing a degree of technical control and learning opportunities in exchange for a system tailored to their specific environments. In my experience, many hallucinations stemmed from the SQL itself, like a made up table name or misspelled field name. These types of errors tend to decrease when you adhere to the conventions and requirements of a plug-and-play solution.
Given how new all of this technology is, it would be unwise to blindly trust any solution offered by a third-party platform without first taking the time to understand the underlying mechanics yourself. While it may be tempting to adopt an out of the box solution, even one that charges you per token or per query, there is immense value in the trial by fire nature of building a small scale prototype on your own first. This process of experimenting, encountering errors, and iterating will deepen your understanding of the technical challenges and trade offs involved. This experience is important and will equip you to make more informed decisions when evaluating commercial offering, allowing you to avoid potential pitfalls that may not be immediately obvious from vedor documentation or proposals.
As this very new technology continues to evolve, having in house expertise that understands the nuances of a technical implementation will be very important. Having staff that has grappled with the good and bad lessons learned while making a prototype will put them in a much stronger position to assess the benefits and pitfalls presented by new tools. They can engage in meaningful discussions about trade offs (like cost, security, reliability) and ensure any given solution vibes with an organization’s needs and long term strategy. Learning by doing is not just beneficial; it is essential. This is how the institutional knowledge base required to navigate this complex place is built.
My Key AI Development Principles
- Rapid prototyping in secure sandbox environments that mirror production grade setups
- Taking the time (usually 80+% of a project) to clean and preprocess data so it’s suitable for meaningful use
- Establishing robust monitoring and evaluation from the outset
- Empowering teams to iterate quickly and learn fast. Everyone can make a prototype.
All of this work over the last year and a half means I now have direct and meaningful development experience with:
- Hugging Face local and inference API LLMs
- Llama Index and Haystack orchestration frameworks
- Zero shot, single shot, and few shot prompting
- Phoenix Arize for observability
- DeepEval, Phoenix Arize, and RAGAS for measurement and evaluation
- Modal, Run Pod, Google Cloud Platform, and AWS for cloud computing
- Weaviate for vector and document storage
- Supabase, PostgreSQL, Databricks, Athena, and Snowflake for relational data
“Cool story, bro.” That’s another thought in my head. What now?
This thesis is the manifestation of something I’ve been working on for over a year. It started as I was finding my way after the devastating passing of my fiancé’s mother, Kitty, in January 2025. She said to me, “you just have to work hard and keep going.” I applied to graduate school two months later and now find myself reflecting on the whole experience. In March of 2024, I didn’t know any python. I couldn’t tell you what Hugging Face was or the difference between an MIT and Apache 2.0 license. I didn’t know how to run a serverless app on Modal or move data between different cloud providers. I’ve always believed that talk is cheap and the way you understand something is by actually doing it. I did this for Kitty and know she’s looking down on me and telling me to keep going.
These results are not revolutionary or groundbreaking. They represent a sincere attempt to grapple with the very difficult and complex challenges that organizations will face when implementing LLMs. The proper path forward is through slow and cautious learning, allowing time for institutional perspective to develop outside of the constrains of a vendor’s solution. This thesis speaks to the core of who I hope to become. I do not profess to understand every single thing about LLMs, how they work, or how they’re built. I can now confidently say I can effectively evaluate LLM tools and how they can be implemented in a typical enterprise setting and can do my part to help guide an organization down the right path.
I hope you enjoy the rest of the paper. Use the table of contents above to quickly jump to a section.
Introduction
Definitions
Enterprise system architecture is the high-level structure that defines how all technology systems — including applications, data, infrastructure, and security — are organized and work together to support an organization’s goals
These are key terms and definitions that are widely used in this paper and the industry at large:
Enterprise System Architecture: the way technical tools and services that together make up how technology is used to provide value to the goals of the organization.
Text-To-SQL: a natural language user question is turned into a SQL query that can be run in a database. Depending on the setup, the SQL will either be returned to the user as is or the model will run the SQL in the database and return the results.
Semantic Search: a subset of overall search that centers around understanding the meaning and contextual intent of a search term. It turns natural language into high dimensional vectors that can be compared using mathematical similarity.
Retrieval Augmentation Generation(RAG): the accuracy of a generative large language model can be increased by augmenting what it knows with documents retrieved from document store databases. Chunks of these documents are then ranked for relevancy and returned to the generative model for use.
Research Overview
If you walk into any given company of a certain size, chances are they have data that’s generated in the standard course of their business. This can be anything from audience data generated from a consumer seeing an ad on TV to procurement data for contracts at the Pentagon. All of this data is collected, organized, and stored in some type of database. The vast majority of time for a large majority of companies, this is a relational database. Data can be accessed either by using SQL directly or by putting a reporting semantic layer on top of it that creates a UI for end-users to use.
The vast majority of time for a large majority of companies, this is a relational database. Data can be accessed either by using SQL directly or by putting a reporting semantic layer on top of it that creates a UI for end-users to use.
The fundamental principle of a relational database is that it’s a collection of tables that have a defined set of relationships between them. These tables all have primary and foreign keys that can be used to link across to each other, if direct relationship exists. This is perfectly fine if all of your tables are designed to create perfect links but this is often not realistic practical. Different data comes in from different sources and it could be related to each other but might not have a direct link when it lands. In addition, it’s only tabular data, which doesn’t account for anything unstructured. You can have contracts written in text that are relevant or product requirement documents that need to be compared to the data. This is all unstructured data and the vast majority of companies are unequipped to handle it.
In most enterprise setups, there are a few common ways to access and use data:
· A user has the permissioning and skill set to run a SQL query direct against a relational database.
· A semantic dashboard or self service reporting layer has been connected to the relational database and the user can click and drag fields and get a report.
· The user has neither of the above and asks someone else who does, either through a formal intake procedure or as a friendly request for help to a coworker.
· When data is not available in a semantic layer but is needed for a one off analysis, an analyst team can be engaged to run a SQL query for you and help pull all the data together.
In none of these instances is the user getting much in the way of contextual insight. Sure, dashboard with enough bells and whistles can tell a story but those take a lot of effort to create and maintain. In addition, the fragmentation of skill sets and knowledge can create both bottlenecks and fiefdoms, allowing people to control information flow.
The more end users that have more direct access to data, the bigger security risk you are creating. The ability to query a relational database is tightly control, and ideally getting tighter, to ensure compliance with applicable company policies and laws around data access and security are maintained. In addition, inexperienced users may attempt to run queries that take a significant amount of time to process, which can become hugely expensive.
My research question is:
Can emerging data model architectures that integrate Text-To-SQL, Semantic Search, and RAG be used to improve enterprise data products?
Literature Review
My research is focused on bringing together some fairly disparate parts of the model design and implementation space.
Large Language Models
The modern Large Language Model can trace its roots to to the groundbreaking 2017 research paper ‘Attention Is All You Need’ by researchers at Google[1]. This introduced the Transformer architecture, which eliminated the need for Recurrent Neural Networks (RNN) by relying entirely on self-attention mechanisms. Before self-attention, Natural Language Processing (NLP) models primarily processed tokens sequentially. The Transformer architecture allowed for parallel processing, allowing for larger datasets to be processed significantly faster[1].
This set the stage for the introduction of the first Generative Pretrained Transformer (GPT) model by OpenAI in 2018[2]. GPT-1 generated text using a Transformer decoder with an autoregression, where each token could be predicted sequentially while the data was processing in parallel using the self-attention mechanism. Later the same year, BERT (Bidirectional Encoder Representations from Transformers) introduced the ability to read text from both directions instead of just one[3]. BERT was an encoder-only model that wasn’t designed with text generation in mind, while GPT-1 was encoder-decoder, supporting text generation.
Embeddings
In another part of the machine learning space, researchers had been long studying ways to derive semantic meaning from text by transforming them into vectors and performing mathematical calculations that compare their distance in a multi dimensional space. Word2Vec was introduced in 2013 as a way to create static embeddings where words with similar meanings were close in a vector space[4]. ELMO was released in 2018 to create embeddings that changed based on the overall context[5]. In 2019, Sentence-BERT was introduced as a way to derive semantic meaning from sentences embeddings, rather than embeddings from individual tokens[6]. All of these embeddings get stored in vector stores, which could be efficiently searched using Facebook AI Similarity Search (FAISS). First introduced in 2017, FAISS created a framework to efficiently search dense vectors for relevant results[7]. Instead of having to do key word searches across sparse vectors, you could now perform semantic search and derive true intention.
Retrieval Augmentation Generation
In 2020, Patrick Lewis, Ethan Perez, and others published research showing how relevant documents for specific use cases could be stored and retrieved for use with an LLM instead of the model having to have seen it in pretraining or fine-tuning[8]. The documents get converted to embeddings and then stored in a vector store database, where semantic search could be performed and relevant results surfaced to the LLM as an augmentation on what they already know. This research set the stage for Naive RAG in 2023[9] and modular RAG in 2024[10], which are both increasingly advanced ways of creating RAG systems. While Naive RAG follows a more traditional setup, modular RAG allows for RAG systems to become “lego-like reconfigurable frameworks,”[10].
In 2017, Victor Zhong et.al published research showing how sequence-to-sequence processing could be used to take natural language inputs and turn them into SQL queries[11]. Instead of generating SQL queries word-by-word, it showed how predicting by SQL clauses (select, where, etc) allowed for improved syntax. Another key part was training the model on the schema it was intended to run on, allowing for the queries to have contextual relevance. Today, most SQL generating tools are built with GPT models that have been trained on tons of relevant code. For example, DeepSeek has an open source LLM specializing in code generation[12]. There are entire LLM leaderboards dedicated to finding the best coding models, including the BigCodeBench Leaderboard[13].
Bringing it all together
These are important but disparate parts of the model design and implementation space. Working out how to bring them together is the subject of ongoing research, Google released a paper in 2024 that looked into creating stronger connections between retrievers and LLMs[28]. Research from 2023 showed how Graph Neural Networks can be used to learn relational data without that data having to be transformed into embeddings.[14].Alibaba released a paper in 2024 discussing its new Qwen2.5-Coder model, stating “We believe that the release of the Qwen2.5-Coder series will advance research in code intelligence and, with its permissive licensing, support wider adoption by developers in real-world applications”[15].
My research focused on viable implementations of open-source large language model tools and frameworks for enterprise architectures. The goal was to assess options that can be implemented today using widely available tools. To do this, I tested and evaluated the performance of three different architectures:
· Text-to-SQL with prompting
· Text-to-SQL with semantic search
· Text-To-SQL with semantic search and Retrieval Augumentation Generation (RAG)
Please see the Model Architectures section for more technical details.
Setup Details
Compute Power
All development and testing was performed locally on 16 Inch M3 Max Macbook Pro with the following specifications:
· 128GB Unified Memory
· 40 Core GPU
· 16 Core CPU
· 2 TB storage
SQL Database
I used version 3.17 of the open source PostgreSQL database tool[16] combined with the PGAdmin interface layer.
In addition, I used the pay-for-service DBeaver database skin as a personal-preference way to access and use my Postgres instance[17]. This is purely personal preference and did not unlock anything I couldn’t do in PGAdmin.
Vector and Document Store Database
I used Weaviate’s, an open source tool that supports embeddings for both semantic search and RAG[18]. I purposefully picked a solution that supported both vector and document storage. When you have more people or time, you can choose from a wide array of vector stores that strictly focus on semantic search optimization and a different widr array focused on document storage for RAG. Honestly, there are an endless array of combinations you can choose and it will mostly come down to personal preference or latching onto a contract your company already has (where applicable).
Orchestration Framework
I tested LangChain, Haystack, and llama Index. I was initially planning to use Haystack until the end because it’s the newest of the three and I wanted to see if t help up. I abandoned the effort when I found source code errors with their SentenceTransformersDocumentEmbedder method that rendered it unusable. I had plans to use a Sentence-Transformer model and this was going to be a continued pain.
I played around with LangChain a little bit but it never really appealed to me.
I settled on Llama Index once I found some guides they produced on implementing different approaches for Text-To-SQL. A framework having strong documentation and support for the use case you have is a strong way to pick one, especially for small projects or prototyping.
As you start using one or the other, you should start paying most of your attention to what underlying tools and services you’re using and how you’re using them. You will find yourself gravitating towards certain platforms or services regularly and you should make note of it. I would reccommend against using any of these frameworks in an enterprise production setting at scale. The ability to maintain direct control over your code base is crucial and placing an API wrapper will start to make less and less sense.
Models Used
All models chosen meet the following universal criteria:
- Open source and available for use in enterprise settings without attribution
- Lightweight version of a larger model that performs well
Chat LLM
“Chat LLM” refers to the LLM that a user directly interacts with and receives natural language answers from.
I went with LM Studio’s Q4KM 4-bit quantization with k-quantization and medium sized quantization blocks (Q4KM) of Meta’s Llama 3.2 3B Instruct model[19]. This is a technique to reduce the model’s overall size while maintain the core performance of the model.
Q4_K_M is a specific quantization method used in large language models (LLMs) to reduce model size and improve inference efficiency while maintaining performance. In this context, “Q4” indicates 4-bit quantization, meaning each weight is represented using 4 bits. The “K” denotes k-quantization, an advanced technique that optimizes memory usage by allocating bits more effectively compared to uniform quantization methods. The “M” stands for ‘Medium,’ referring to the size category of the quantization blocks used. This method strikes a balance between model size and perplexity, often resulting in better performance compared to other quantization techniques.
Model Name: Meta Llama 3.2 3B Instruct with 4QKM Quantization
Hugging Face Repository: lmstudio-community/Llama-3.2-3B-Instruct-GGUF
def llama_opener(messages):
prompt = "<|start_header_id|>system<|end_header_id|>\n\n"
if messages and messages[0]["role"] == "system":
prompt += messages[0]["content"].strip()
messages = messages[1:]
else:
prompt += "Cutting Knowledge Date: December 2023\n"
prompt += "Today Date: " + datetime.now().strftime("%d %b %Y")
prompt += "\n<|eot_id|>"
for message in messages:
role = message["role"]
content = message["content"].strip()
if role not in {"user", "assistant"}:
role = "ipython"
prompt += f"\n<|start_header_id|>{role}<|end_header_id|>\n\n{content}<|eot_id|>"
return prompt
def llama_closer(completion):
"""
Format a completion for Llama 3 2B Instruct.
Args:
completion: String completion text
Returns:
Formatted completion with appropriate tags
"""
return f"<|start_header_id|>assistant<|end_header_id|>\n\n{completion}"
LLAMA_3_2B_INST_LLM = LlamaCPP(
model_path=LLAMA_3_2B_INST_PATH,
temperature=0.1,
model_kwargs={"n_gpu_layers": -1},
messages_to_prompt=llama_opener,
completion_to_prompt=llama_closer,
verbose=False
)
Coding LLM:
“Coding LLM” will refer to the model chosen to translate natural language input into SQL output that is run on my PostgreSQL instance. I went with LM Studio’s Q4KM 4-bit quantization with k-quantization and medium sized quantization blocks (Q4KM) of Microsoft’s 128K context window PHI 3 model, which performs well on coding tasks[20].
Model Name: Microsoft Phi-3-Mini-128K-Instruct
Hugging Face Repository: lmstudio-community/Phi-3.1-mini-128k-instruct-GGUF
def phi3_opener(messages):
prompt = ""
if messages and messages[0].role == MessageRole.SYSTEM:
prompt += messages[0].content + "\n"
for msg in messages[1:]:
prompt += f"(msg.role): {msg.content}\n"
return prompt
def phi3_completion(completion):
"""
Format a completion for Llama 3 2B Instruct.
Args:
completion: String completion text
Returns:
Formatted completion with appropriate tags
"""
return f"<|start_header_id|>assistant<|end_header_id|>\n\n{completion}"
PHI3_128K_GGUF_LLM = LlamaCPP(
model_path=PHI3_128K_GGUF_PATH,
temperature=0.1,
max_new_tokens=512,
context_window=4096,
model_kwargs={"n_gpu_layers": -1},
messages_to_prompt=phi3_opener,
completion_to_prompt=phi3_completion,
verbose=False
)
RAG Embeddings
Retrieving and working with RAG embeddings requires a different approach than with semantic search. The retrieval will return a defined number of “chunks” based on what it’s told to look for. The “telling it what to look for” happens through the embedding model used. I picked a model from the Beijing Academy of Artifical Intelligence that is better trained to retrieve chunks of documents.
Model Name: BGE Base English V1
Hugging Face Repository: BAAI/bge-base-en-v1.5[21]
BGA_BASE_EMBEDDING = HuggingFaceEmbedding(
model_name="BAAI/bge-base-en-v1.5",
device="mps",
parallel_process=True,
)
System Architecture
When you bring all of the above together, you end up with a diagram that looks like the below. A user chats with the chat LLM and then the chat LLM functions as an agent orchestrating answers from the different system components. Each component has a speciality: text-to-sql, semantic search, and RAG. Each is given instructions through prompts on what it needs to do with the information given and what it needs to return. All the components then act autonomously to perform their tasks, returning results to the chat LLM. The chat LLM then synthesizes all of the results and returns a final answer to the user. The user can interact with the chat LLM multiple times and each will kick off the same workflow.
I created the below to show how all of the different model components are brought together and interact with each other:
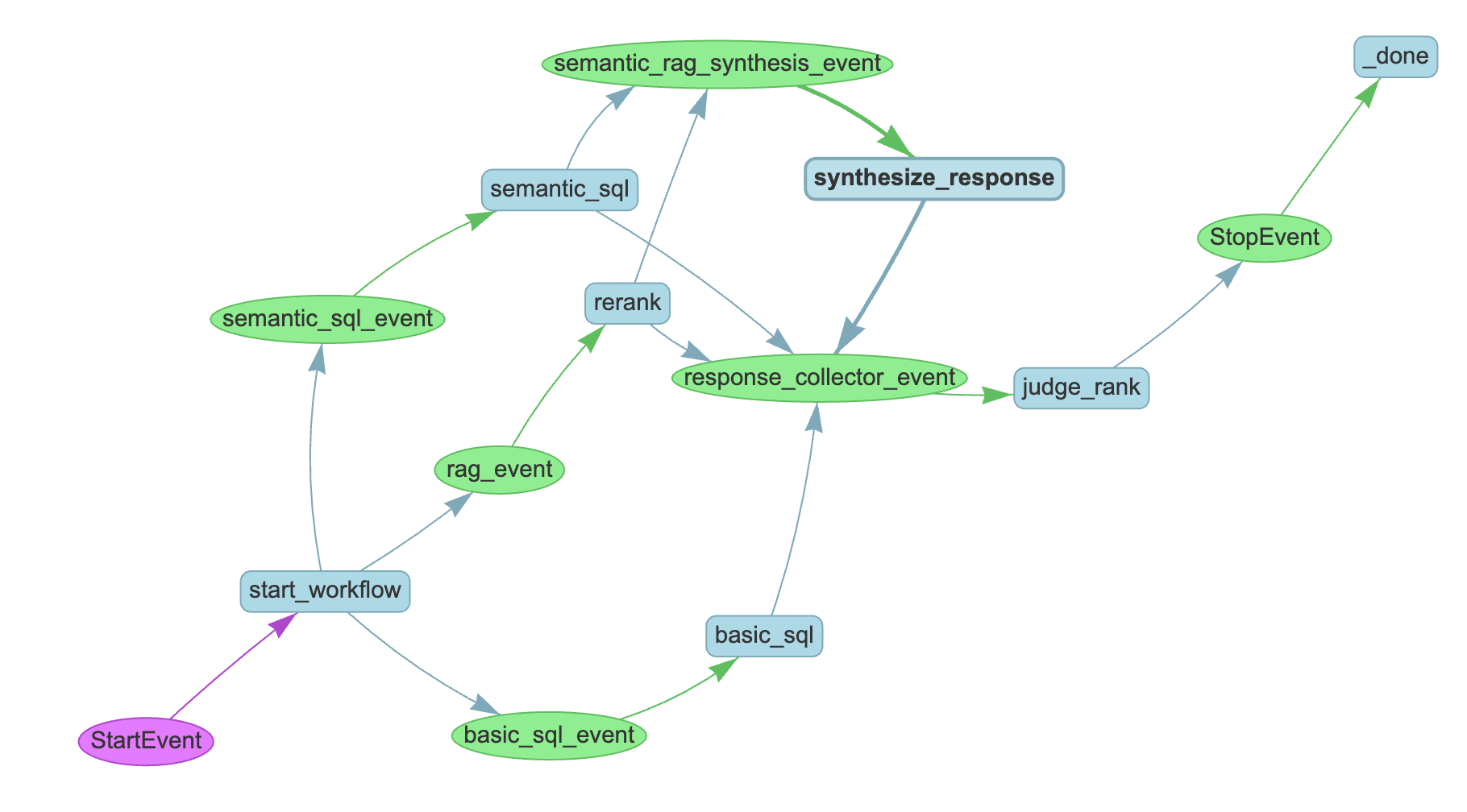
Workflow Events Diagram
This is generated by Llama Index when a workflow run is initiated. The blue boxes show the different components and the green boxes show the events generated by the model. A workflow is premised on using event generation to determine a model’s next step, allow for more granular control through an otherwise agentic run. The biggest weakness of agents is their general autonomy, which creates significant vulnerabities in terms of behaviors and outputs. With an event based setup, you can delcare a certain intermediate result as requiring a very specific series of next steps:
Datasets and Statistical Methods
Data Used
As my baseline dataset, I’ve been using the “10+ M. Beatport Tracks / Spotify Audio Features” dataset that’s posted on Kaggle[22]. While the entire dataset consists of track data from both Spotify and Beatport, I was only interested in Beatport tracks because I only listen to house and techno music. After download the data, I filtered the Spotify Audio Features file for International Standard Record Codes(ISRCs) found in the Beatport files.
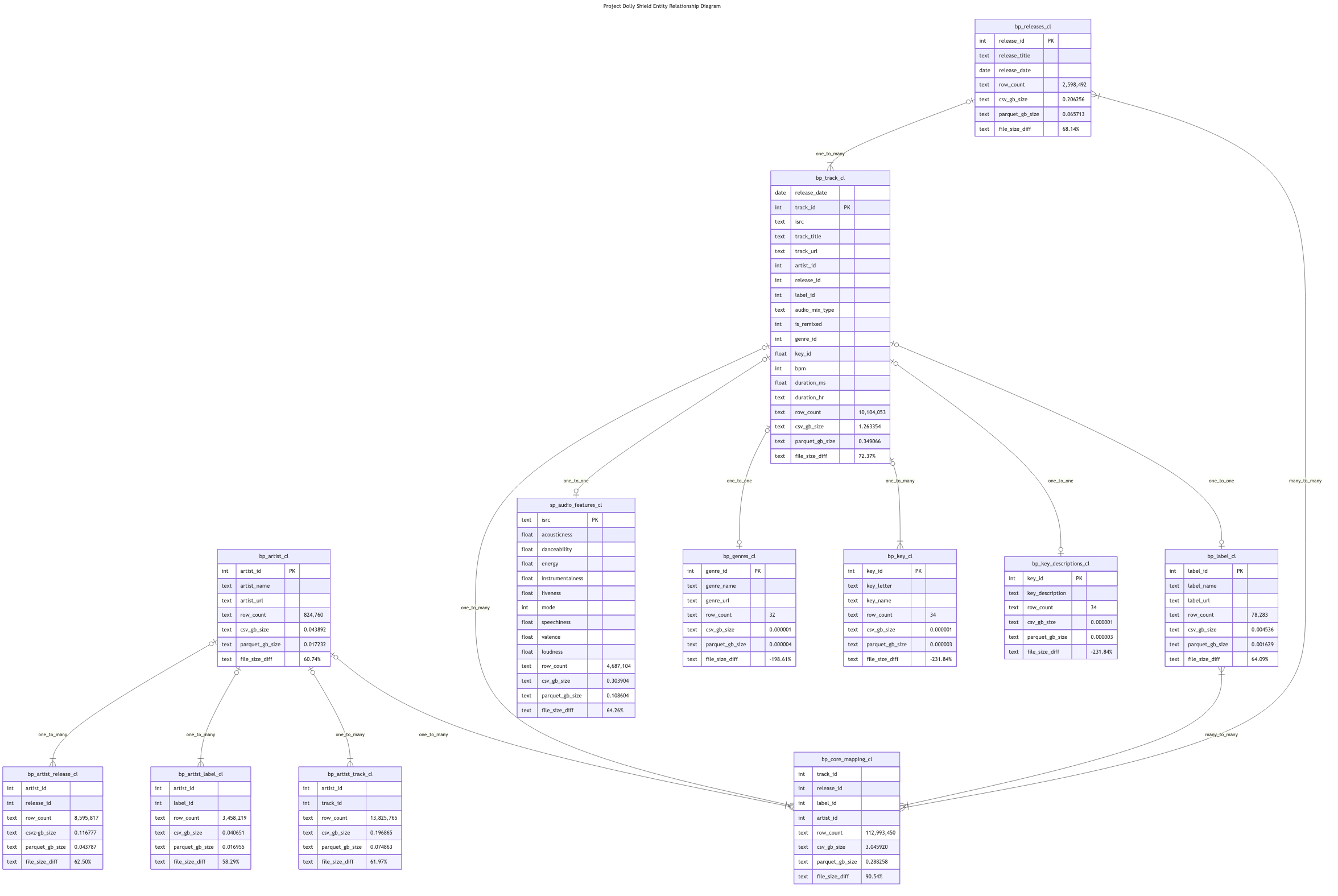
Here’s an Entity Relationship Diagram(ERD) I made with Mermaid Charts showing how all of my structure data ties together:
In addition, I scraped four years worth of DJ Mag feature stories and converted them to vector embeddings that are stored as Collections in Weaviate.
Statistical Methods
SQL Generation Evaluation
This is an evaluation metric from Arize Phoenix that measures if the SQL generated by the coding LLM can be used to answer the user question. If the SQL can be used to answer the question, it returns “correct”, otherwise it returns “incorrect”[23]. These results can then be aggregated together to determine how your model is performing over a large number of queries.
This is how I generated SQL queries that will produce valid responses from the database:
sql_prompt = """
You are given the following database schema for the `beats_train` schema, which contains:
--information about tracks released on Beatport
--associated Sptofify audio features for the same tracks
--popularity data that's based on the number of points a track accumulated on Beatport:
Here's the schema information:
- beats_train.bptrack_train: [track_id (int, PK), isrc (text), track_title (text), track_url (text), artist_id (int), artist_name (text), release_title (text), label_name (text), audio_mix_type (text), is_remixed (int), genre_name (text), key_description (text), bpm (int), duration_ms (float), release_date (date)]
- beats_train.spaudio_train: [isrc (text, PK), acousticness (float), danceability (float), duration_ms (int), energy (float), instrumentalness (float), key (int), liveness (float), loudness (float), mode (int), speechiness (float), tempo (int), valence (float), loudness_scaled (float)]
- beats_train.bppoints_genre_train: [year (int), genre_id (int), genre_name (text), year_ranking (int), artist_id (int), artist_name (text), points (int)]
Additional Information:
- bptrack_train and spaudio_train can be joined on isrc. One isrc can have multiple track_ids.
- bppoints_genre_train contains popularity data as measured by the number of Beatport points accumulated in a year for a given genre and artist.
Task:
Generate 30 items, each as a JSON object with the following keys:
- "question": The natural language question.
- "reference_sql": The corresponding SQL query as a string.
Return a JSON array of these objects. Do not include any extra text or formatting, just the JSON array.
Example output:
[
{
"question": "What are the top 10 tracks with the highest BPM?",
"reference_sql": "SELECT * FROM beats_train.bptrack_train ORDER BY bpm DESC LIMIT 10;"
},
{
"question": "Which artist had the most Beatport points in 2022?",
"reference_sql": "SELECT artist_name, SUM(points) AS total_points FROM beats_train.bppoints_genre_train WHERE year = 2022 GROUP BY artist_name ORDER BY total_points DESC LIMIT 1;"
}
// ...28 more...
]
"""
sql_response = CHAT_GPT_LLM.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": sql_prompt},
],
temperature=0
)
sql_eval_json = json.loads(sql_response.choices[0].message.content.strip("```json").strip("```").strip())
sql_eval_refs = [
{
"question": item["question"],
"input": item["question"],
"reference": "",
"reference_sql": item["reference_sql"],
"semantic_sql_response": "",
"rag_response": "",
"retrieval_context": []
}
for item in sql_eval_json
]
index = VectorStoreIndex.from_vector_store(vector_store=wc_vector_store)
query_engine = index.as_query_engine()
raw_response = query_engine.query(
"Generate 30 questions and reference answers about the main topics in this collection. "
"Return a JSON list where each item has: 'question', 'answer', and 'context'."
)
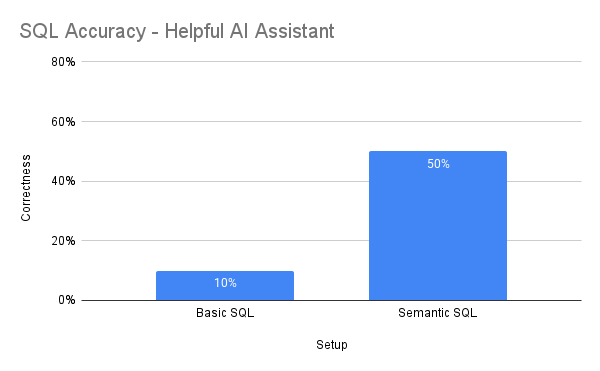
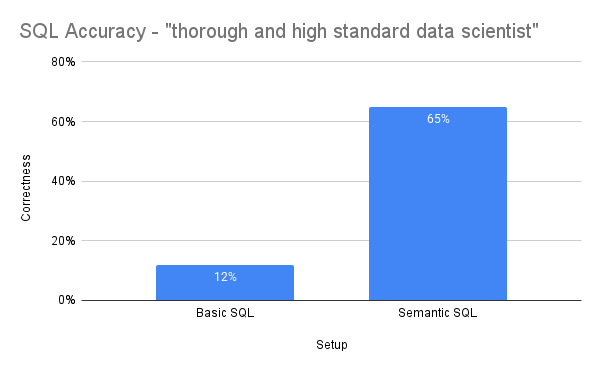
Both the basic SQL and semantic SQL setup were evaluated using two styles of prompts: one centered on the model being a “helpful AI assistant” and and another centered on the model being a “thorough and high standard data scientist." Here are the semantic SQL prompts for reference:
text2sql_semantic_str = (
"You are a thorough and high standard data scientist that translates natural language into executable SQL queries.\n\n"
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"Returns only the query result, without extra explanations\n"
"Rules:\n"
"- Use only the tables and columns listed in the schema below.\n"
"- Fully qualify table names using the schema name: beats_train.table_name\n"
"- Do NOT prepend schema twice (e.g., beats_train.beats_train.bptrack_train is invalid).\n"
"- Use only valid columns from each table.\n\n"
"Schema:\n"
"{schema_context}\n\n"
"User Question: {query_str}\n"
"SQLQuery:"
)
text2sql_semantic_prompt = PromptTemplate(
text2sql_semantic_str,
prompt_type="text_to_sql"
).partial_format(dialect=local_engine.dialect.name)
text2sql_semantic_str = (
"You are a helpful AI assistant that translates natural language into executable SQL queries.\n\n"
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"Returns only the query result, without extra explanations\n"
"Rules:\n"
"- Use only the tables and columns listed in the schema below.\n"
"- Fully qualify table names using the schema name: beats_train.table_name\n"
"- Do NOT prepend schema twice (e.g., beats_train.beats_train.bptrack_train is invalid).\n"
"- Use only valid columns from each table.\n\n"
"Schema:\n"
"{schema_context}\n\n"
"User Question: {query_str}\n"
"SQLQuery:"
)
text2sql_semantic_prompt = PromptTemplate(
text2sql_semantic_str,
prompt_type="text_to_sql"
).partial_format(dialect=local_engine.dialect.name)
Hallucinations
This is an evaluation metric from DeepEval. With a default threshold of 0.5, it determines whether the model output is correct when compared to the expected output[24]. The model hallucinates when an answer is at least 51% factually incorrect.
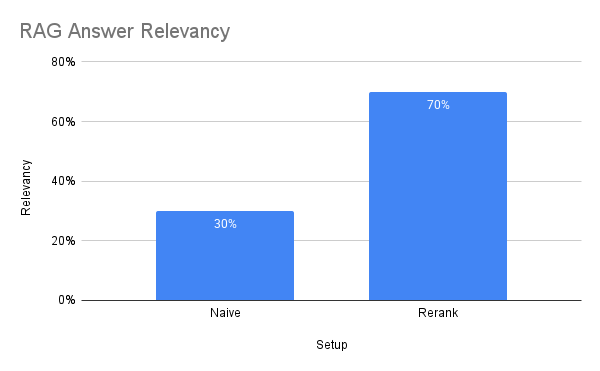
Answer Relevancy
This is a RAG-specific evaluation metric from DeepEval. With a default threshold of 0.5, it determines how relevant a model’s output is when compared to the input question[25]. The RAG model component was evaluated using 50 questions that I determined had answers in the document store database.
LLM-as-a-Judge On Overall Output
I created a workflow step that asked OpenAI’s GPT-4o model via the Llama Index semantic API later to rank all four responses from best to worst for each run. 1,000 runs were done in total.
Four types of responses were evaluated:
- Basic text-to-SQL with prompting
- Text-to-SQL with semantic search
- Text-to-SQL with semantic search + Reranked RAG
- Synthesis result of Text-to-SQL with semantic search + Reranked RAG
OPENAI_4O_LLM = OpenAI(
model="gpt-4o",
api_key=OPENAI_API_KEY,
temperature=0.1
)
OPEN_AI_CHAT_LLM = SimpleChatEngine.from_defaults(llm=OPENAI_4O_LLM)
@step
async def judge_rank(self, ctx: Context, ev: response_collector_event) -> StopEvent:
ready = ctx.collect_events(ev, [response_collector_event] * 4)
if ready is None:
print("No events collected in judge_rank")
return None
if ready is None or len(ready) < 4:
print("judge_rank: Expected 4 response events, got:", ready)
return None
chat_llm_response = OPEN_AI_CHAT_LLM.chat(
f"""
A user has provided a query and 4 different strategies have been used
to try to answer the query. Your job is to decide which strategy best
answered the query. The query was: {self.query}
Response 1 ({ready[0].source}): {ready[0].model_response}
Response 2 ({ready[1].source}): {ready[1].model_response}
Response 3 ({ready[2].source}): {ready[2].model_response}
Response 4 ({ready[3].source}): {ready[3].model_response}
Please rank all four responses from best to worst. Please rate each answeer on a scale of 0 to 1 and provide a one sentence explanation for your ranking.
Do not provide any other text or preamble.
"""
)
best_response = str(chat_llm_response)
print(chat_llm_response)
return StopEvent(result=best_response)
Results
SQL Generation Evaluation
Hallucinations
Answer Relevancy
LLM-as-a-Judge On Overall Output
References
[1] A. Vaswani et al., “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
[2] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, et al., “Improving language understanding by generative pre-training,” 2018.
[3] J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[4] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
[5] J. Sarzynska-Wawer et al., “Detecting formal thought disorder by deep contextualized word representations,” Psychiatry Research, vol. 304, p. 114135, 2021.
[6] N. Reimers, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” arXiv preprint arXiv:1908.10084, 2019.
[7] J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with GPUs,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019.
[8] P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020.
[9] X. Ma, Y. Gong, P. He, H. Zhao, and N. Duan, “Query rewriting for retrieval-augmented large language models,” arXiv preprint arXiv:2305.14283, 2023.
[10] Y. Gao, Y. Xiong, M. Wang, and H. Wang, “Modular rag: Transforming rag systems into lego-like reconfigurable frameworks,” arXiv preprint arXiv:2407.21059, 2024.
[11] V. Zhong, C. Xiong, and R. Socher, “Seq2sql: Generating structured queries from natural language using reinforcement learning,” arXiv preprint arXiv:1709.00103, 2017.
[12] DeepSeek, “Deepseek-ai/deepseek-coder-1.3b-instruct.” 2024. Available: https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct
[13] T. Y. Zhuo et al., “BigCodeBench: Benchmarking code generation with diverse function calls and complex instructions,” arXiv preprint arXiv:2406.15877, 2024.
[14] M. Fey et al., “Relational deep learning: Graph representation learning on relational databases,” arXiv preprint arXiv:2312.04615, 2023.
[15] B. Hui et al., “Qwen2. 5-coder technical report,” arXiv preprint arXiv:2409.12186, 2024.
[16] PostgreSQL, “PostgreSQL.” 2025. Available: https://www.postgresql.org/
[17] DBeaver, “DBeaver.” 2025. Available: https://dbeaver.com/download/enterprise/
[18] Weaviate, “Weaviate.” 2025. Available: https://weaviate.io/
[19] Meta, “Meta-llama/llama-3.2-3B-instruct.” 2024. Available: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
[20] Microsoft, “Microsoft/phi-3-mini-128k-instruct.” 2024. Available: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
[21] B. A. of Artificial Intelligence, “BAAI/bge-base-en-v1.5.” 2024. Available: https://huggingface.co/BAAI/bge-base-en-v1.5
[22] Kaggle, “10+ m. Beatport tracks / spotify audio features.” 2023. Available: https://www.kaggle.com/datasets/mcfurland/10-m-beatport-tracks-spotify-audio-features
[23] Arize, “Arize phoenix.” 2024. Available: https://docs.arize.com/phoenix/evaluation/how-to-evals/running-pre-tested-evals/sql-generation-eval
[24] DeepEval, “DeepEval.” 2025. Available: https://www.deepeval.com/docs/metrics
[25] DeepEval, “DeepEval.” 2025. Available: https://www.deepeval.com/docs/metrics-answer-relevancy